A. Namachivayam and Kaliyaperumal Karthikeyan
Eritrea Institute of Technology, Asmara, Eritrea, North East Africa.
Article Publishing History
Article Received on :
Article Accepted on :
Article Published : 02 Jul 2014
Article Metrics
ABSTRACT:
The paper introduces a face recognition method using probabilistic subspaces analysis on multi-module singular value features of face images. Singular value vector of a face image is valid feature for identification. But the recognition rate is low when only one module singular value vector is used for face recognition. To improve the recognition rate, many sub-images are obtained when the face image is divided in different ways, with all singular values of each image used as a new sample vector of the face image. These multi-module singular value vectors include all features of a face image from local to the whole, so more discriminator information for face recognition is obtained. Subsequently, probabilistic subspaces analysis is used under these multi-module singular value vectors. The experimental results demonstrate that the method is obviously superior to corresponding algorithms and the recognition rate is respectively 97.5% and 99.5% in ORL and CAS-PEAL-R1human face image databases.
KEYWORDS:
face recognition; probabilistic subspaces analysis; multi-module; singular value decomposition
Copy the following to cite this article:
Namachivayam A, Karthikeyan K. Multi-module Singular Value Decomposition for Face Recognition. Orient. J. Comp. Sci. and Technol;7(1)
|
Copy the following to cite this URL:
Namachivayam A, Karthikeyan K. Multi-module Singular Value Decomposition for Face Recognition. Orient. J. Comp. Sci. and Technol;7(1). Available from: http://computerscijournal.org/?p=638
|
INTRODUCTION
In recent years, computer vision research has witnessed a growing interest in subspace analysis techniques. And the important problem is how to extract the valid discriminator features for face recognition. The Karhunen-Loève Transform(KLT) and Principal Component Analysis are examples of eigen vector-based reduction and features extraction. A maximum a posteriori (MAP) matching rule using a Bayesian similarity measure derived from dual probabilistic has been applied for face recognition in. These methods have the disadvantages of the recognition performance easily affected by the facial expressions, large pose and variable illumination. A number of improved methods have been proposed. For example, the method using combination of wavelet packets and PCA/LDA have improved the face recognition rate, and Gabon representation based on probabilistic subspaces analysis for face recognition have also gotten the improvement of the face recognition, and so on. Their success shows that the traditional approaches applied in the different feature spaces can get the better recognition performance. Singular value features of matrix are widely used in the data compression, signal processing and pattern analysis, because they have the following features: the good stability, the proportional and rotational invariant. The singular value features of face images are firstly applied to face recognition in. The research of showed enough information needed could not be gotten for face recognition by using only one module singular value decomposition of whole face and the more features must be extracted. The paper introduces the face recognition method based on multi-module singular value features and probabilistic subspaces analysis (MSVD+PSA). Firstly, the sub-images are obtain when the face image is divided in different ways, then all singular value of each sub-image is organized and used as the sample vector of the face image.
Finally, the method of probabilistic subspaces analysis is applied to the all sample vectors of face images. The remainder of the paper is organized as follows: In Section 2, the idea of the proposed method is described. The experimental results are presented for the ORL and CASPEAL-R1 face image databases to demonstrate the effectiveness and robustness of our method in section 3.Finally, conclusions are presented in Section 4.
II. OUR FACE RECOGNITION METHOD
A. Multi-module Singular Value Decomposition The singular value decomposition (SVD) is one of the most important tools of numerical signal processing. It is employed in a variety of signal processing application, such as spectrum analysis, filter design, system identification etc. In singular value decomposition it has several advantages of computational efficiency and robustness under noise conditions. Singular value decomposition of matrix a (m× n) cane written as follows
A = ∧ VT
Where-The columns of U are the eigenvectors of AAT. U is anm×m matrix containing an ortho normal basis of vectors for both the columns space and left null space of A. For orbit correction, the orbit vector will be expanded in terms of the basis vectors in U. In linear algebra, U contains the left singular vectors of A.Λ – The ‘singular values’ or ‘principle gains’ of A lie on the diagonal of Λ and are the square root of eigenvectors of both AAT and ATA, that is, the eigenvector in U and the eigenvector of V share the same eigenvalues.V – The rows of VT (columns of V) are the eigenvectors of AAT. S an n × n matrix containing an ortho normal basis of vectors for both the row space and right null space of A. The column vector of corrector magnets vector will be expanded interims of the basis vectors in V. V contains the right singular vectors of A. We introduce the method of multi-module singular value decomposition. The i-by-i sub-matrices p A (where p is the total number of sub-matrices, and if i ×i × p ≠ m× n , the face image matrix A is filled by zero to ensure the both sides of the equation are equal) are gained when the face image matrix A is divided in different ways. The sub-matrices p A office image is shown in Figure 1 when the modules p is 16.
The singular values (1, 2, p) of all sub-matricesAk are calculated by (1). Finally, the singular values Ikare organized as follows
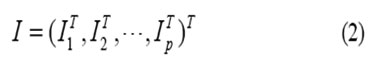
So, I (where the size of I is i-by-p) is used the sample vector of the matrix A. Because of the finite size of face image matrix A, the divided number of face image matrix A is also finite.
Formula 4
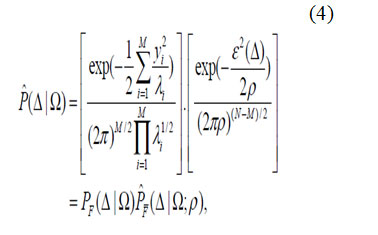
B.Probabilistic Subspace Analysis on the Singular Value of the Face Image
Based on the above results, we obtain a training set of vectors {I t}, where I ∈RN =ip and t is the total number of training sample, by lexicographic ordering of the pixel elements of each matrix. The basis function for the KLT are obtained by solving the eigen value problem
Formula3
A = Φ T ∑Φ
Where Σ is the covariance matrix, Φ is the eigenvector matrix of Σ, and Λ is the corresponding diagonal matrix of eigenvalues. The unitary matrix Φ defines a coordinate transform (rotation) which de-correlates the data and makes explicit the invariant subspaces of the matrix operator Σ. InPCA, a partial KLT is performed to identify the largest eigen value eigenvectors and obtain a principal component feature
Formula
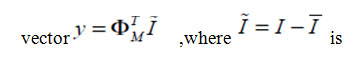
the mean normalized vector and is a sub-matrix of Φ containing the principal eigenvectors. PCA can be seen as a linear transformation y = Γ(I ) : RN→ RMwhich extracts a lower dimensional subspace of the KL basis corresponding to the first M largest eigenvalues. These principal components preserve the major linear correlations in the data and discard the minor ones. By ranking the eigenvectors of the KL expansion with respect to their eigenvalues and selecting the first M principal components, we form an orthogonal decomposition of vector space RN into two mutually exclusive and complementary subspaces(or feature space) F = {Φ1} i = M+1N the principal subspace (or feature space)containing the principal components and its orthogonal complement In practice there is always a signal component in F due to the minor statistical variability in the data or simply due to the observation noise which affects every element of I. The complete likelihood estimate can be written as the product of two independent marginal
Gaussian densities where is true marginal density in F, is the estimated marginal density in the orthogonal complement F ,yi are the principal components, and ε2(Δ) is the PCAresidual (reconstruction error). The information-theoretic optimal value for the density parameter ρ is derived by minimizing the Kullback-Leibler (KL) divergence and is found to be simply the average of the F eigenvalues
Formula 5
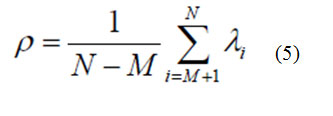
In their formulation, the above expression for ρ is the maximum-likelihood solution of a latent variable model as opposed to the minimal-divergence solution.
C. Classification
We now consider the problem of characterizing the type of differences which occur when matching two images in apace recognition task. We define two distinct and mutually exclusive classes: ΩI representing intrapersonal variations between multiple images of the same individual (e.g., with different expressions and lighting conditions), and ΩErepresenting extra personal variations which result when matching two different individuals. We will assume that both classes are Gaussian-distributed and seek to obtain estimates of the likelihood functions P (Δ |ΩI) and P (Δ |ΩE) for a given intensity difference Δ = I1 − I2 .Given these likelihoods we can define the similarity scores(I1,I2) between a pair of images directly in terms of intrapersonal a posteriori probability as given by Bayes rules:
Formula6
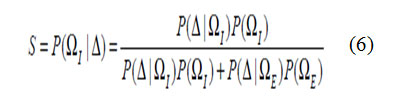
Where the priors P(Ω) can be set to reflect specific operating conditions (e.g., numbers of test images vs. the size of the database) or other sources of a priori knowledge regarding the two images being matched. Additionally, this particular Bayesian formulation casts the standard face recognition task(essentially an M-ary classification problem for M individuals)into a binary pattern classification problem with and ΩE.This much simpler problem is then solved using the maximum posteriori (MAP) rule——i.e., two images are determined to belong to the same individual P(ΔΩ1)> l P(ΔΩE), or equivalently, if S(I1,I2) >1/2.
III. EXPERIMENTAL RESULTS
A. Experiment on the ORL Database
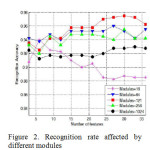
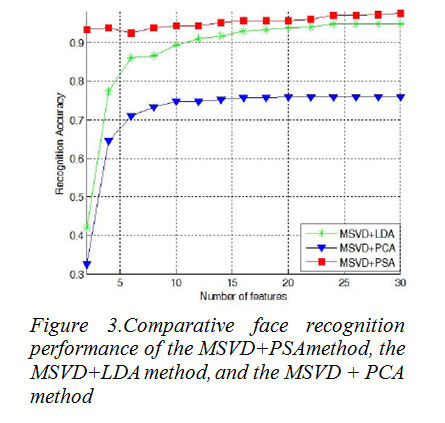
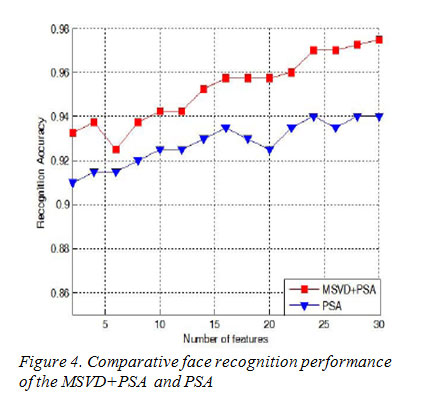
The proposed method is tested on ORL face database. Database has more than one image of an individual’s face with different conditions (expression, illumination, etc). There are ten different of each of 40 distinct subjects. Each image haste size of 112×92 pixels with 256 levels of gray. For some subjects, the images were taken at different times, varying the lighting, facial expressions (open/close eye, smiling/not smiling) and facial details (glasses / no glasses). All the Images were taken against a dark homogeneous background with the subjects in an upright, frontal position (with tolerance for some side movement). The original pictures of 112×92pixels have been resized to 64×64 so that the input space haste dimension of 4096.In our experiment, as five images are chosen for training, the remaining images (unseen during training) are used for testing. Thus, the total number of training samples and testing samples is 200, respectively. Training set is composed as follows: the first five images in per class for training, named Set 1; the behind five images in per class for training, named Set 2. The final result is the average of the Set1 and Set2.As the modules of the face image increase, the recognition rate is improved in Figure 2. When the modules are equal to121, the recognition performance achieves the best result. But the modules are more than 121, there is lower recognition rate. This shows the recognition performance are greatly affected by the divided modules of original image, and the way of combination of multi-module singular value features and probabilistic subspaces analysis can be improvement of the recognition performance. For comparison purpose, we first implemented the MSVD+PSA method, the MSVD+LDA method, and the MSVD + PCA method. We use the modules of the face image are equal to 121 in the experiment, and the recognition rate is the average of Set1 and Set2. The comparative face recognition performance of these three methods is shown in Figure 3. One can see from the figure that the MSVD+PSA method perform better than other methods. Especially, when the number of features is very little, the MSVD+PSA method keeps the high recognition rate. We compare the MSVD+PSA and PSA method (wherePSA method using the grey-value of original image). The result from Figure 4 show the MSVD+PSA method can achieve the recognition rate of 97.5%, but the PSA method only can get the best recognition rate of 94%. It also shows theMSVD+PSA method outperforms PSA.
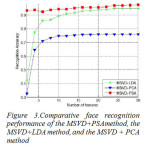 |
Figure3:Comparative face recognition performance of the MSVD+PSAmethod, the MSVD+LDA method, and the MSVD + PCA method
Click here to View Figure |
B. Experiment on the CAS-PEAL-R1 Database
CAS-PEAL-R1 Database is a large face database, containing 30863 images of the 1040 subjects. The experiments involve 1200 face images corresponding to 200subjects such that each subject has six images of size 360×480 with 256 gray scale levels. The face image is cropped to the size of 64×64 to extract the facial region, which is further normalized to zero mean and unit variance. Figure 5 shows some example images used in our experiments that are already cropped to the size of 64 × 64. Note that they especially display different facial expressions.
CONCLUSION
We have introduced in the paper a novel multi-module singular value features and probabilistic subspace analysis classification. The proposed method, which is robust to variations in illumination and facial expression, applies the PSA method to the organized singular value features derived from the multi-module of the face image. These multi-module singular value vectors include all features of a face image from local to the whole, so more discriminate information for pattern recognition is obtained. So the recognition rate of the proposed method for face recognition is higher than those of other methods in the image domain. The feasibility of our method has been successfully tested on face recognition signor and 1200 CAS-PEAL-R1 frontal face images corresponding to 200 subjects, which were acquired under variable illumination and facial expressions. The novel our method achieves respectively 97.5% and 99.5% accuracy on face recognition of ORL and CAS-PEAL-R1 face databases.
REFERENCES
- Tian Yuan, Tan Tie-niu, Wang Yun-hong. “Do singular values containadequate information for face recognition”, Pattern Recognition, vol.36,no.6, pp:649-655, 2003.
- Esther Annlin Kala James, Dr.S.Annaduai, etal. “Implementation of incremental linear discriminant analysis using singular value decomposition for face recognition”, ICAC,2009.
- BabackMoghaddam, Alex Pentland. “Probabilistic visual learning for object representation” , IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 19, no. 7, pp. 696-710, July 2007.
- BabackMoghaddam. Watching Wahid and alexPenland. “Beyongeigenfaces: probabilistic matching for face recognition”, proc. Int’l conf.Automatic Face and Gesture Recognition (FG’98),pp.30-35. Apr.1998.
- PN. Belhumeure, J.P. Hespanha, D.J. Kriengman, “Eigenfaces vs.fisherfaces: recognition using class specific linear projection,” IEEETrans. Pattern Analysis and Machine Intelligence, vol. 19, pp. 711-720,July 1997.
CrossRef
- W. .Gao, B.Cao, “The CAS-PEAL large-scale Chinese face database and baseline evaluations,” IEEE Transactions on Systems, Man, and Cybernetics, vol. 38, pp. 149-161, January, 2008
CrossRef

This work is licensed under a Creative Commons Attribution 4.0 International License.