INTRODUNCTION
The mining of association rules is performed in two stages:
The discovery of frequency sets of items from the data and the generation of association rules from frequency item set. The first stage is computationally intensive
And the second stage has the drawback of possible generating thousands of rules, thus making the analysis of the results has to perform by a human analyst.
Our contribution relate to both stages of this process. We analyze stage one and introduce two new algorithm among which algorithm Closure improves upon the performance of the classic algorithm Apriori. We define the concept of an informative cover of the set of association rules and present algorithm cover rules for computing such a cover, which is in practice one or more orders of magnitude smaller than the set of association rules.
Next, we investigate how the mining of association rules should be performed when the data reside in several tables organized in a star scheme. We show how to modify the Apriori algorithm to compute the support of item sets by analysis the star scheme table or their outer join. Whereas association rules express the dependency between item sets, purity dependencies express the dependency between sets of attributes. We introduce the concept of purity dependency as a generalization of the concept of functional dependency and we show that these purity dependencies satisfy properties that are similar to the Armstrong rules for functional dependencies. As an application of our theory we present an algorithm for discovering purity dependencies that can be used to predict the value of a target attribute.
1.2 Data Mining as Process
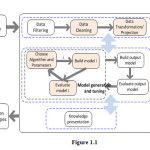
Figure 1.1 presents a generic model for the DM process, with the main logical steps involved. The colored-background boxes represent steps for which original contributions will be presented throughout this dissertation.
Knowledge presentation employs visualization methods to display the extracted knowledge in an intuitive, accessible and easy to understand manner. Decisions on how to proceed with future iterations are made based on the conclusions reached at this point.
1.3 Knowledge Extraction Tasks
The purpose of a data mining system is defined through the desired employment mode. According to [Fay96], two main categories of goals can be distinguished: verification and discovery. Description tasks generate models and present them to the user in an easy-to-understand form. Summarization and visualization, clustering, link analysis and outlier analysis represent descriptive tasks. Prediction tasks generate models for predicting future behavior of certain entities. Classification, regression and time series prediction are the main tasks falling in this category.
A dataset is a finite set T of elements, named instances, or examples
T = { xi | i=1 to m } (2.1)
An instance xi is a tuple of the form (x(1), …, x(n), y)i, where x(1), …, x(n) represent values for the predictive attributes (features), while y is the value of the target attribute, the class:
xi = (x(1), …, x(n), y)i (2.2)
Classification
Classification problems try to determine the characteristics which correctly identify the class to which each instance belongs to. Thus, the scope is to learn a model from the training set which describes the class Y, i.e. predict y from the values of (a subset of) (x(1), …, x(n)). The resulting model can be employed either for descriptive, or predictive tasks. Classification is similar to clustering, the main difference being that, in classification, the class to which each instance in the dataset belongs to is known a priori.
The main categories of classification methods
ASSOCIATION RULES
The Association rules1 problem has been introduces in [AIS93b] in the context of analyzing supermarket data. We begin our discussion of this problem with an analysis of possible organization of data.
An association rule is defined as the implication X → Y, described by two interestingness measures—support and confidence—where X and Y are the sets of items and X ∩ Y =Ø.
The following is a formal statement of the problem: Let I = {i1, i2,…, im} be a set of literals, called items. Let D be set of transactions, where each transaction is set of items. Associated with each transaction is a unique identifier, called its TID. We say that a transaction T contains X, a set of some items in I, I f X C T.
An association rule is an implication of the form- X → Y, where
X⊆ I, Y⊆ I and X ∩ Y=∅
• Association rule X→ Y has confidence c if c% of transactions in D that contain X also contain Y.
• Association rule X→ Y has support s, if s% of transactions in D contains X U Y.
The problem of mining association is to generate all association rules that have support and confidence greater than the user-specified minimum support and minimum confidence in a given set of transactions D.
DATABASE CONSIDERATION
The supermarket data analyzed in[2] has a simple formal model, Let I={i1,i2,…..in}be a set whose elements are called items and let T={t1,t2,…tm}be a multi set whose elements transactions, where each transaction ti represents a subset of I . The multi set T can be stored in a special table with binary attributes I and an additional transaction identifier attribute tid. Such a table is called a binary table or binary database.
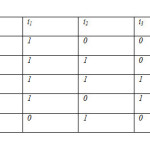 |
Table1.2: shows the contents of a binary table for I={i1,i2,i3} and T={{i1},{i2},{i3},{i1,i2},{i1,i3},{i2,i3},{i1,i2,i3}}.
Click here to View table
|
In a binary table, the presence of an item in a transaction is indicated by a value of I for the attribute corresponding to the item, and its absence is indicated by a 0.Thus, the cardinality of the domain of the attributes corresponding to items is two. In most tables used in practice it is infrequent to have only binary attributes. Attributes that take values in a limits domain are called nominal or categorical attributes, and attributes whose domain is large are called numerical attributes. In the case of a nominal attribute, we will extend the use of the term item to designate a particular attributes-value pair (A, a). Denoting A= a (e.g. Color=red). Numerical attributes are handled by transforming them to nominal attributes through the process of dividing their domain into intervals and assigning identifies to these intervals. For example, for an attributes age we could assign the identifier teenager for the age interval 10-19, resulting in item age=teenager. This transformation numerically attributes into nominal attributes is called discretization.
Contemplating Table 1.2. We can also consider the problem of data density. Intuitively, we consider one binary database to be denser than another when its attributes take the value 1 more often. We say that a database is sparse when its rows contain a relatively small number of 1’s, otherwise we call the database dense. These notions are informal, however, as there is no formal measure for quantifying the density of a database.
1.2.2 Problem definition
We begin by defining the central concepts of the AR mining problem. For historical reasons , the terminology that was introduced in[1] in the context of analyzing supermarket data has been kept intact in all successive papers published on this subject, even when the paper discussed different application.
Definition 1.1 Let I= {i1, i2,……..in} be a set whose elements are called items and let T= {t1,t2,……tn} be a multiset whose elements are called transactions. Where each transaction ti⊆ I. A subset of I is called itemset. An item set of cardinality k is call k-itemset. The support of an itemset I is denoted by SUPP(I) and defined as
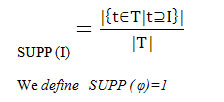
We define SUPP ( φ)=1
An association rule is an implication of the form A → C, where a A and C are two disjoint itemsets call antecedent and consequent, respectively. We refer to the antecedent and consequent of a rule r by using the notations antc (r) and cons(r ) . We refer to the items of rule r by items(r)=antc(r ) ∪ cons(r). The support of an association rule r is defined as:
Supp(r) =supp (items( r )).
The confidence of an association rule r is defined as
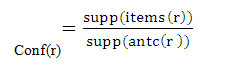
Note that the support of an itemset or rule, and the confidence of a rule, take value in the interval [0,1]. To simplify the notation, we will use t1, t2, t3to denote the itemsets {i1, i2, i3}. In most algorithms, itemsets are actually implemented as lists where the items appear in lexicographic order, which allows them to be processed easily and efficiently.
In {AIS93b], the AR problem was divides into two sub problems:
- Finding all frequent itemsets.
- Generating all association rules starting from the frequent item sets found.
Finding all frequent itemsets is the more computationally intensive of the two subproblems and research efforts have focused on finding more efficient algorithms. Some methods search for only a subset of all frequent itemsets that has the property of summarizing or of allowing to infer the information on all frequent itemsets. For example, this subset can represent the set of large itemsets [Bay98] or the set of closed3 itemsets [2].
1.1.2.1 Mining frequent itemsets
ALGORITHMS: The different algorithms used in data mining are given below-
Apriori is the first algorithm proposed in the association rule mining field and many other algorithms were derived from it. Starting from a database, it proposes to extract all association rules satisfying minimum thresholds of support and confidence. It is very well known that mining algorithms can discover a prohibitive amount of association rules; for instance, thousands of rules are extracted from a database of several dozens of attributes and several hundreds of transactions.
1. APRIORITID ALGORITHM:
The interesting feature of this algorithm is that it uses the database only once. [not used for counting support after first pass].The set C^k is used for that purpose. Each member of set is in form < TID, {Xk} >, where Xk are potentially large k-items in transaction TID.
For k=1, C^1 is the database.
L1= {large 1-itemsets}
C^k =database D;
For (k=2; L k-1 ≠ ∅; k++) do begin
Ck=apriori-gen (Lk-1);
C^k=∅;
Forall entries t ∈ C^k-1 do begin
Ct = {c∈ Ck|(c-c[k] ∈ t.set-of-items ∧ (c-c [k-1]) ∈ t.set-of-items};
Forall candidates’ c∈ Ct do
c.count++;
If (ct≠∅) than C^k +=< t.TID, Ct>;
End
End
Lk= {C∈ C^k \c. count ≥minsup}
end
ANS =
Advantages:
1.1.1C^k could be smaller than the database. If a transaction does not contain k-itemset candidates, than it will be excluded from C^k
1.1.2 For large k, each entry may be smaller than the transaction. The transaction might contain only few candidates
Disadvantage
For small k, each entry may be larger than the corresponding transaction because an entry includes all k-item sets contained in the transaction.
REFERENCE
- Rakesh Agrawal,Tomasz Imielenski :”Mining Association Rulles between sets of items in large database”. In Proceedings of ACM-SIGMOD International Conference on management of data,in PP-207-216,1993
- Nicolas Pasquier,Yves Bastide,Rafik Taouil and Lotfi Lakhal.”Discovering frequent Closed Itemsets for Association Rules.” In Proceeding of the 7th International conference on Database Theory.PP. 398-416,1999.
CrossRef

This work is licensed under a Creative Commons Attribution 4.0 International License.