A Comparative Analysis of Classification Algorithms on Weather Dataset Using Data Mining Tool
D. Ramesh*  , Syed Nawaz Pasha and G.Roopa
, Syed Nawaz Pasha and G.Roopa
Department of CSE, S R Engineering College Warangal 506371, Telangana, India.
Corresponding author Email: dadiramesh44@gmail.com
DOI : http://dx.doi.org/10.13005/ojcst/10.04.13
Article Publishing History
Article Received on : 17-10-2017
Article Accepted on : 11-12-2017
Article Published :
Article Metrics
ABSTRACT:
Data mining has become one of the emerging fields in research because of its vast contents. Data mining is used for finding hidden patterns in the database or any other information repository. This information is necessary to generate knowledge from the patterns. The main task is to extract knowledge out of the information. In this paper we use a data mining technique called classification to determine the playing condition based on the current temperature values. Classification technique is a powerful way to classify the attributes of the dataset into different classes. In our approach we use classification algorithms like Decision Tree (J48), REP Tree and Random Tree. Then we compare the efficiencies of these classification algorithms. The tool we use for this approach is WEKA (Waikato Environment for Knowledge Analysis) a collection of open source machine learning algorithms.
KEYWORDS:
Classification; Data Mining; Data set
Copy the following to cite this article:
Ramesh D, Pasha S. N, Roopa G. A Comparative Analysis of Classification Algorithms on Weather Dataset Using Data Mining Tool. Orient.J. Comp. Sci. and Technol;10(4)
|
Copy the following to cite this URL:
Ramesh D, Pasha S. N, Roopa G. A Comparative Analysis of Classification Algorithms on Weather Dataset Using Data Mining Tool. Orient. J. Comp. Sci. and Technol;10(4). Available from: http://www.computerscijournal.org/?p=7204
|
Introduction
Data mining is that the method to extract or mine data from immense volume of information. Broadly data processing will be outlined because the task of extracting implicit, antecedent unknown potential helpful data from knowledge in giant databases. Data mining tasks are classified as descriptive which discover interesting patterns or relationships describing the data and predictive task which predicts or classifies the behavior of the model supported obtainable information. It’s a content field with a general goal of predicting outcomes and uncovering relationships. Some of the data mining techniques are Classification, Clustering and Rule Mining.
Clustering is that the most typically used information discovery technique. It helps un-covering the unknown category labels. It helps un-covering the unknown class labels. Clustering has gained importance in many applications in the recent past. Most of the cluster algorithms area unit ascendable to large dataset. Weather is random entity. Forecasting is the technology to predict the atmosphere at given location and a given time taking into consideration various factors such as humidity, temperature, wind and outlook.. It’s done by gathering the information regarding this state of the atmosphere at a given location thus applies scientific understanding to predict but the temperature will modification over the course of some time. In our paper we are going to predict whether the play can happen based on current weather values such as temperature, humidity, windy, outlook.11 We make the prediction based on various classification algorithms such as Decision Tree (J48), REP Tree and Random Tree. We conjointly compare every of those algorithms in terms of their accuracy mistreatment completely different measures.
Classification algorithms
Decision Tree Induction
DTI is a tree learning algorithms. It consists of flow diagram like structure wherever the inner node denotes a take a look at on the attribute, the branches will denote the outcome of the test performed on the attribute and the leaf nodes will denote class labels.
The internal nodes are represented as rectangles and the leaf nodes are represented with oval shapes.
To determine the cacophonic attribute it makes use of various attribute choice measures like data gain, gain quantitative relation and Gini Index.
Example: J48,C 4.5,CART
REP Tree
It is a decision tree learner algorithm. It constructs the decision tree exploitation data gain or variance then prunes it exploitation reduced error pruning exploitation back fitting strategy.REP Tree Iteratively generates multiple trees using regression logic. It sorts the values for numeric attribute only once. It deals with missing values by rending the corresponding instances into items.
Random Trees
This algorithm can deal with both regression and classification problems. it’s a group of tree predictors that’s referred to as forest. It takes the input as feature vector and compares it with each tree within the forest and offers the result category label that has highest votes.
Classifier Output Measures
The classifier classifies the tuples in the dataset. It is quite natural that the classifier may have error rate and may fail to correctly classify the tuples.Hence we measure the classifier accuracy which is given by the percentage of instances that square measure properly classified by classifier.
Confusion Matrix
It gives information regarding the classifier output in terms of the number of tuples that are correctly classified and the numbers of tuples that are miss classified. For a good accuracy classifier the elements must be in along the diagonal while the other entries must be close to zero.
Mean Absolute Error
It is a measure for accuracy. It is the mean of the absolute errors that is the mean of the distinction between the expected value and also the actual value.
Root Mean Square Error
If we take the square root of the mean square error then we obtain the root mean square error. We do it to adjust large error rates.
Results and Comparisons
The tool we used for the result analysis is WEKA which consists of large number of open source machine learning algorithms. It takes the input in the form of ARFF (Attribute Relation File Format),CSV(comma separated values).The data set we used is weather which is input to weka in ARFF format.
The weather data set contains following attributes.
The dataset has 14 instances
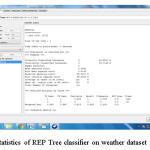
Result of REP Tree Classifier
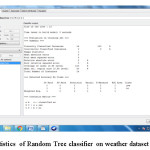
Result of Random Tree
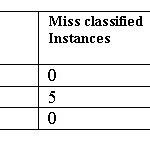
Overall comparison of J48, REP Tree and Random Tree (using training dataset)
Conclusion
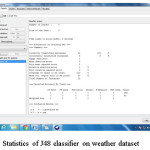
This paper intends to study the classifier accuracy of various classification algorithms using WEKA tool on weather dataset. The experimental results of the various classification algorithms is listed.First the experiment was done on the weather dataset using j48 algorithm which classifies all the instances correctly.The accuracy of the j48 classifier is 100%.Then the dataset was run on Random Tree classifier which classifies all instances correctly and has 100% accuracy.Then classification was done using REP Tree classifier and we found the accuracy was decreased to 64.28% because it was not able to classify all the instances correctly and we found that 5 instances were mis classified by REP Tree classifier because of which its accuracy is decreased.
References
- Bhavani M, Vinod Kumar S “A data mining approach for precise diagnosis of dengue fever”,International journal of latest trends in engineering and technology. 2016;7(4).
- Dr. A. Padmapriya, “Prediction of Higher Education Admissibility using Classification Algorithms”. International Journal of Advanced Research in Computer Science and Software Engineering. Volume 2, Issue 11, November 2012 [4] Qasem A. Al-Radaideh , Eman Al Nagi, “Using Data Mining Techniques to Build a Classification Model for Predicting Employees Performance”. International Journal of Advanced Computer Science and Applications. 2012;3(2).
- Germano C. Vasconcelos, Paulo J. L. Adeodato and Domingos S. M. P. Monteiro. 1999. A Neural Network Based Solution for the Credit Risk Assessment Problem. Proceedings of the IV Brazilian Conference on Neural Networks – IV Congresso Brasileiro de Redes Neurais. 1999;269-274.
- Tian-Shyug Lee, Chih-Chou Chiu, Chi-Jie Lu and I-Fei Chen. Credit scoring using the hybrid neural discriminant technique. Expert Systems with Applications (Elsevier). 2002;23:245–254.
- Dr. Sudhir B. Jagtap, Dr. Kodge B. G, “Census Data Mining and Data Analysis using WEKA”, International Conference in “Emerging Trends in Science, Technology and Management. 2013;10.
- S. Archana1, Dr. K. Elangovan, “Survey of Classification Techniques in Data Mining”, International Journal of Computer Science and Mobile Applications.2014;2(2):11.
- Dr. A. Bharathi, E. Deepan kumar ,” Survey on Classification Techniques in Data Mining”, International Journal on Recent and Innovation Trends in Computing and Communication. 2014;2(7).
- Zan Huang, Hsinchun Chena, Chia-Jung Hsu, Wun-Hwa Chen and Soushan Wu. Credit rating analysis with support vector machines and neural networks: a market comparative study,” Decision Support Systems (Elsevier). 2004;37:543– 558.
CrossRef
- Kin Keung Lai, Lean Yu, Shouyang Wang, and Ligang Zhou. Credit Risk Analysis Using a Reliability Based Neural Network Ensemble Model. S. Kollias et al. (Eds.): ICANN 2006, Part II, Springer LNCS. 2006;4132:
682 – 690.
- Eliana Angelini, Giacomo di Tollo, and Andrea Roli. A Neural Network Approach for Credit Risk Evaluation,” Kluwer Academic Publishers. 2006;1–22.
- S. Kotsiantis. Credit risk analysis using a hybrid data mining model. Int. J. Intelligent Systems Technologies and Applications. 2007;2(4):345–356.
CrossRef
- Hamadi Matoussi and Aida Krichene. Credit risk assessment using Multilayer Neural Network Models – Case of a Tunisian bank. 2007.
- Lean Yu, Shouyang Wang, and Kin Keung Lai. Credit risk assessment with a multistage neural network ensemble learning approach. Expert Systems with Applications (Elsevier). 2008;34:1434–1444.
CrossRef
- Arnar Ingi Einarsson. Credit Risk Modeling. Ph.D Thesis, Technical University of Denmark. 2008.
- Sanaz Pourdarab, Ahmad Nadali and Hamid Eslami Nosratabadi. 2011. A Hybrid Method for Credit Risk Assessment of Bank Customers. International Journal of Trade, Economics and Finance.2011;2(2).
- UCI Machine Learning Data Repository – http://archive.ics.uci.edu/ml/datasets.
- Tina R. Patil, and S. S. Sherekar. Performance Analysis of Naive Bayes and J48 Classification Algorithm for Data Classification. International Journal Of Computer Science And Applications.2013;6(2):256-261.
- Witten IH, and Frank E. Data mining: practical machine learning tools and techniques – 2nd ed. the United States of America, Morgan Kaufmann series in data management systems. 2005.
- Quinlan J. Simplifying decision trees, International Journal of Man Machine Studies. 1987;27(3):221–234.
CrossRef
- S.K. Jayanthi and S.Sasikala. 2013. REPTree Classifier for indentifying Link Spam in Web Search Engines. IJSC. 2013;3(2):498–505.
- Leo Breiman. Random Forests. Machine Learning. 2001;45(1):5-32.
CrossRef
- Margaret H. Danham, and S. Sridhar. Data mining, Introductory and Advanced Topics. Person education, 1st Edition. 2006.
- Lakshmi Devasena, C. Efficiency Comparison of Multilayer Perceptron and SMO Classifier for Credit Risk Prediction. International Journal of Advanced Research in Computer and Communication Engineering. 2014;3(4):6156-6162.

This work is licensed under a Creative Commons Attribution 4.0 International License.